A simple way to add parallel operations to the Pandas dataframes
The library allows you not to think about the number of workers, creating processes and provides an interactive interface for monitoring progress.
Installation
pip install pandas jupyter pandarallel requests tqdmAs you can see, I also install tqdm. With it, I will clearly demonstrate the difference in the speed of code execution in a sequential and parallel approach.
Setup
import pandas as pd
import requests
from tqdm import tqdm
tqdm.pandas()
from pandarallel import pandarallel
pandarallel.initialize(progress_bar=True)You can find the complete list of settings in the pandarallel documentation.
Setup dataframe
For experiments, let's create a simple data frame - 100 rows, 1 column.
df = pd.DataFrame(
[i for i in range(100)],
columns=["sample_column"]
)
Example task
As we know, the solution of not all problems can be paralleled. A simple example of a suitable task is to call some external source, such as an API or database. In the function below, I call an API that returns one random word. My goal is to add a column with words derived from this API to the data frame.
def function_to_apply(i):
r = requests.get(f'https://random-word-api.herokuapp.com/word').json()
return r[0]
The classic way to solve the problem
df["sample-word"] = df.sample_column.progress_apply(function_to_apply)For people not familiar with the tqdm library, I’ll explain that the progress_apply function acts similarly to the usual apply. And in addition to this, we get an interactive progress bar.
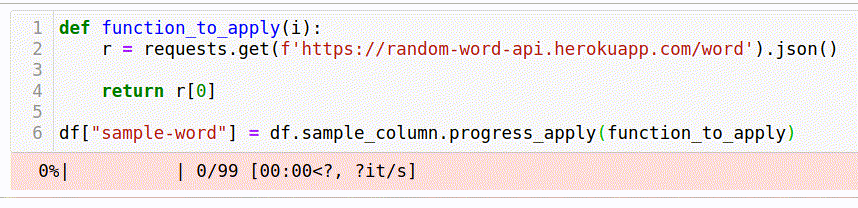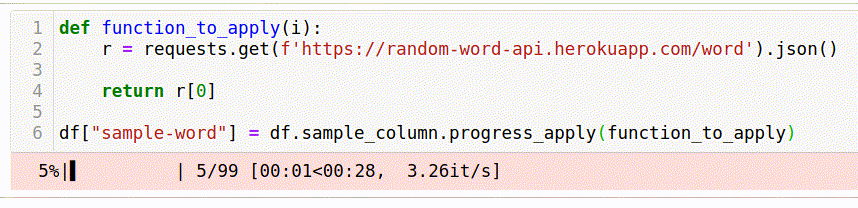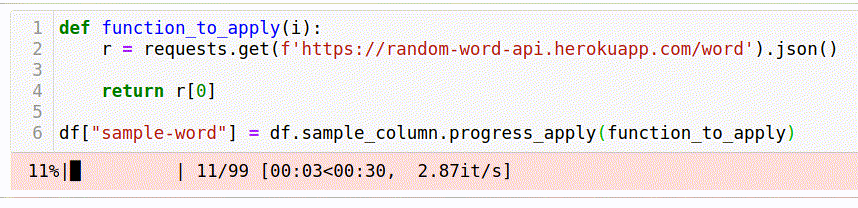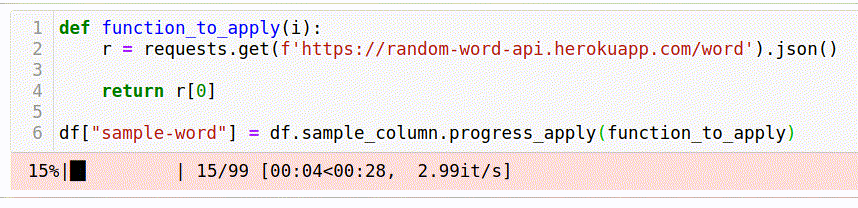
Such a “naive” solution took 35 seconds.
Parallel way to solve the problem
To use all available cores, just use the parallel_apply function:
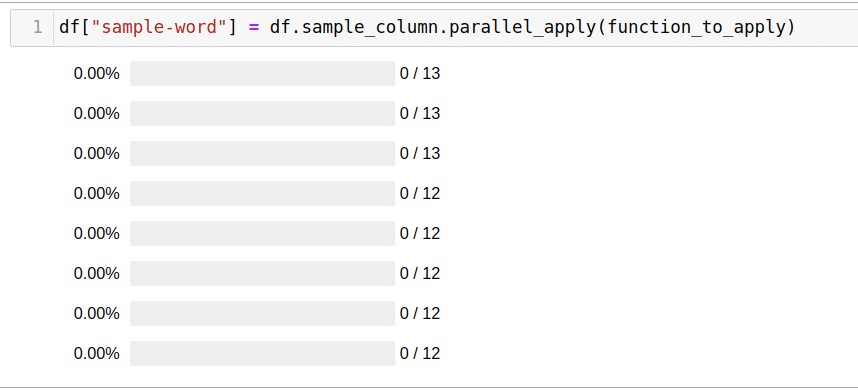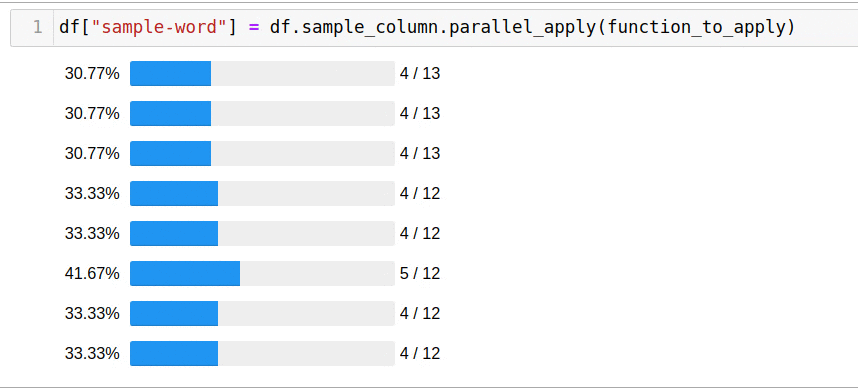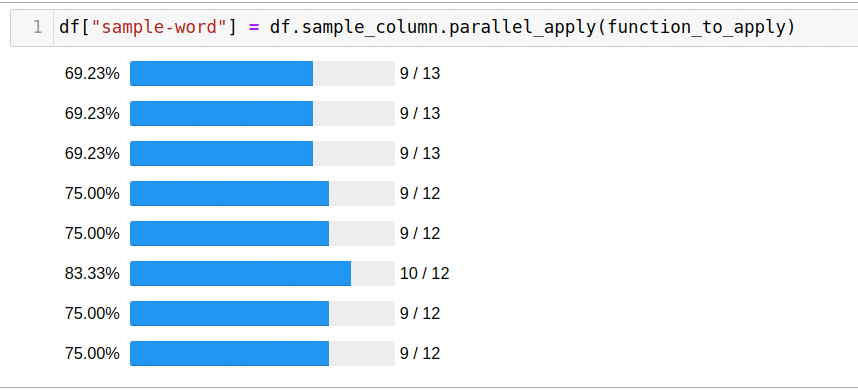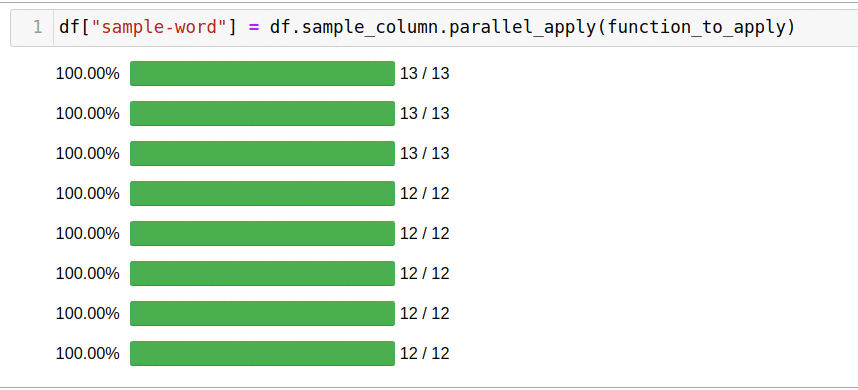
df["sample-word"] = df.sample_column.parallel_apply(function_to_apply)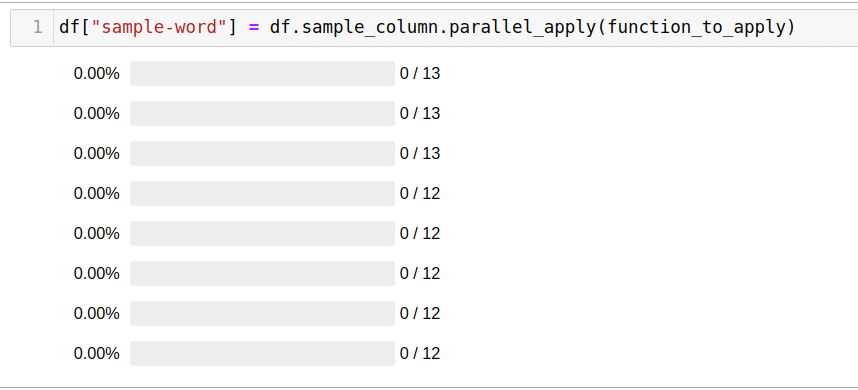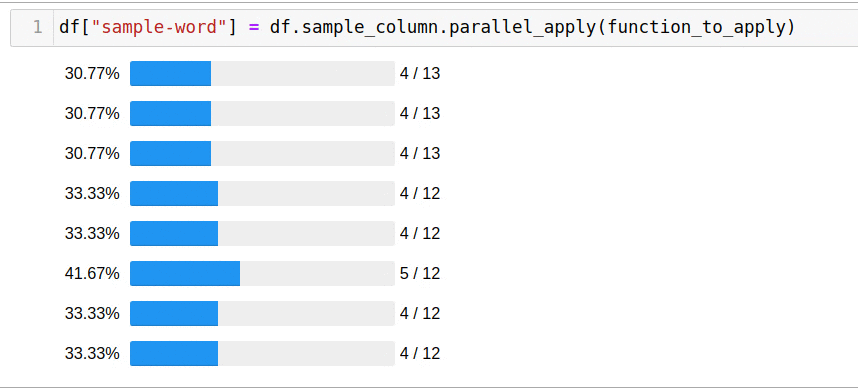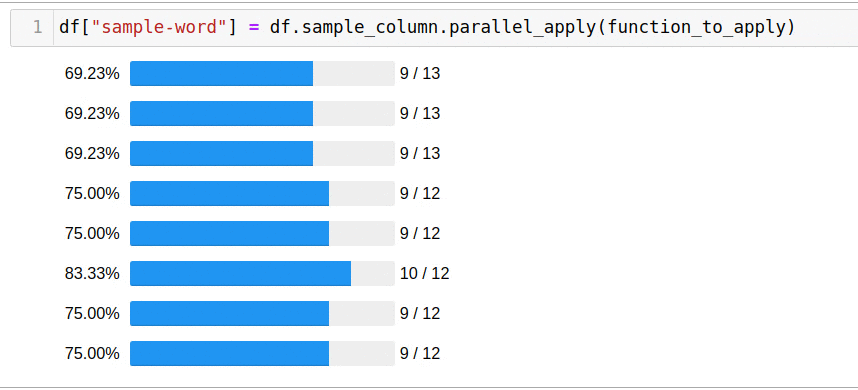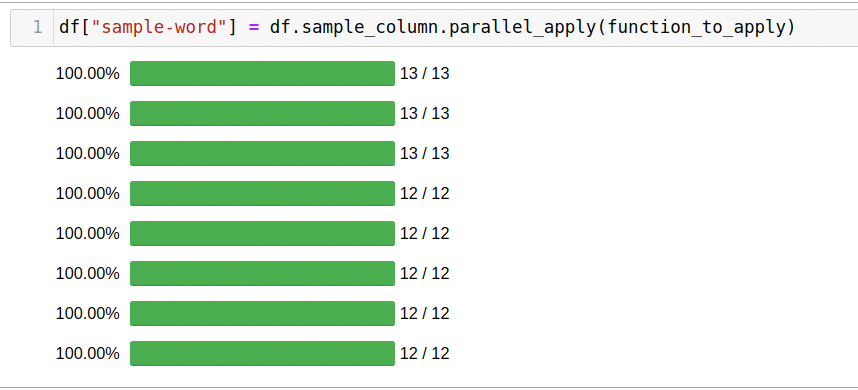
Solving the problem using all available cores took only 5 seconds.
Other scenarios
A full list of pandas features supported by pandarallel is listed on the GitHub project.

Thanks for attention!